阿布云
你所需要的,不仅仅是一个好用的代理。
python模拟自动登陆知乎和tesseract-ocr自动识别验证码

# _*_ coding: utf-8 _*_
'''
模拟知乎登陆并使用tesseract-ocr识别验证码
Author: Insomnia
Version: 0.0.1
Date: 2017-09-07
Language: Python3.6.2
Editor: Sublime Text3
'''
import requests, os, time, re
from bs4 import BeautifulSoup
from PIL import Image
# 当前项目路径
cur_path = os.getcwd() + '/'
class ZhiHuSpider(object):
'''
本类主要用于实现模拟知乎登陆并使用tesseract-ocr识别验证码
Attribute:
session: 建立会话
url_signin: 登陆页面链接
url_login: 登陆接口
url_captcha: 验证码链接
headers: 请求头部信息
num: 识别验证码次数
'''
def __init__(self):
self.session = requests.Session();
self.url_signin = 'https://www.zhihu.com/#signin'
self.url_login = 'https://www.zhihu.com/login/email'
self.url_captcha = 'https://www.zhihu.com/captcha.gif?r=%d&type=login' % (time.time() * 1000)
self.headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
self.num = 1
def get_captcha(self):
'''
获取并使用tesseract-ocr识别验证码
Returns:
返回验证码
'''
# 创建文件夹存放验证码
if not os.path.exists(cur_path + 'captcha'):
os.mkdir(cur_path + 'captcha')
captcha_text = ''
while True:
# 下载验证码图片
captcha = self.session.get(self.url_captcha, headers=self.headers).content
captcha_path = cur_path + 'captcha/captcha.gif' # 验证码图片路径
captcha_path_new = cur_path + 'captcha/captcha_new.gif' # 处理后的验证码图片路径
with open(captcha_path, 'wb') as f:
f.write(captcha)
# 图片处理便于识别文字:彩色转灰度,灰度转二值,二值图像识别
im = Image.open(captcha_path)
w, h = im.size
im = im.convert('L') # convert()用于不同模式图像之间的转换
threshold = 100 # 图片降噪处理
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
im = im.point(table, '1')
w_new, h_new = w * 2, h * 2
im = im.resize((w_new, h_new), Image.ANTIALIAS) # 图片放大
im.save(captcha_path_new)
# 执行tesseract-ocr识别验证码
captcha_text_path = cur_path + 'captcha/captcha_text' # 识别验证码后验证码文字的存放路径
cmd = '/usr/bin/tesseract %s %s' % (captcha_path_new, captcha_text_path)
os.system(cmd)
time.sleep(2)
with open('%s.txt' % captcha_text_path, 'r') as f:
try:
captcha_text = f.read().strip()
print('第 %d 次识别的验证码为:%s' % (self.num, captcha_text))
regex = re.compile('^[0-9a-zA-Z]{4}$') # 正则表达式
if captcha_text and re.search(regex, captcha_text):
break;
else:
print('验证码无效!重新识别中...')
self.num += 1
# time.sleep(2) # 避免过于频繁的访问
except Exception as e:
print('Exception:', e)
break;
return captcha_text
def login(self, username, password):
'''
登陆接口
Args:
username: 登陆账户
password: 登陆密码
Returns:
返回登录结果list
'''
soup = BeautifulSoup(self.session.get(self.url_signin, headers=self.headers).content, 'html.parser')
# 获取xsrf_token
xsrf = soup.find('input', attrs={'name': '_xsrf'}).get('value')
post_data = {
'_xsrf': xsrf,
'email': username,
'password': password,
'captcha': self.get_captcha()
}
login_ret = self.session.post(self.url_login, post_data, headers=self.headers).json()
return login_ret
def get_index_topic(self):
'''
获取首页第一条话题记录
'''
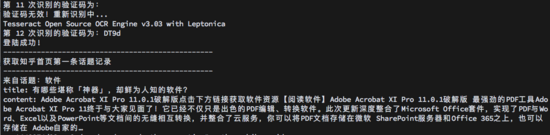
print('-'*50, '获取知乎首页第一条话题记录', '-'*50, sep="\n")
soup = BeautifulSoup(self.session.get(self.url_signin, headers=self.headers).content, 'html.parser')
item = soup.find('div', attrs={'class': 'Card TopstoryItem TopstoryItem--experimentFont18'})
popover = item.find('div', attrs={'class': 'Feed-title'}).find('div', attrs={'class': 'Popover'}).find('div').get_text() # 话题
print('来自话题:%s' % popover)
title = item.find('div', attrs={'class': 'ContentItem AnswerItem'}).find('meta', attrs={'itemprop': 'name'}).get('content') # 标题
print('title: %s' % title)
content = item.find('div', attrs={'class': 'ContentItem AnswerItem'}).find('span', attrs={'class': 'RichText CopyrightRichText-richText'}).get_text() # 内容
print('content: %s' % content)
if __name__ == '__main__':
zhihu = ZhiHuSpider()
# 循环尝试登陆
while True:
ret = zhihu.login('知乎登陆邮箱', '知乎密码')
if ret['r'] == 0:
print('登陆成功! ')
zhihu.get_index_topic()
break
else:
print('登陆失败: %s' % ret['msg'])
运行效果图