阿布云
你所需要的,不仅仅是一个好用的代理。
用Python实现带随机梯度下降的Logistic回归

logistic回归是一种著名的二元分类问题的线性分类算法。它容易实现、易于理解,并在各类问题上有不错的效果,即使该方法的原假设与数据有违背时。
你将了解到:
-
如何使用logistic 回归模型进行预测。
-
如何使用随机梯度下降(stochastic gradient descent)来估计系数(coefficient)。
-
如何将logistic回归应用到真实的预测问题。
描述
本节将简要介绍 logistic 回归算法、随机梯度下降以及本教程使用的 Pima 印第安人糖尿病数据集。
logistic回归算法
logistic回归算法以该方法的核心函数命名,即 logistic 函数。logistic 回归的表达式为方程,非常像线性回归。输入值(X)通过线性地组合权重或系数值来预测输出值(y)。
与线性回归的主要区别在于,模型的输出值是二值(0或1),而不是连续的数值。
yhat = e^(b0 + b1 * x1) / (1 + e^(b0 + b1 * x1))
公式可简化为:
yhat = 1.0 / (1.0 + e^(-(b0 + b1 * x1)))
这里 e 是自然对数的底(欧拉数),yhat 是预测值,b0 是偏差或截距项,b1 是单一输入变量(x1)的参数。
yhat 预测值为 0 到 1 之间的实数,它需要舍入到整数值并映射到预测类值。
输入数据中的每一列都有一个相关系数 b(一个常数实数值),这个系数是从训练集中学习的。存储在存储器或文件中的最终模型的实际上是等式中的系数(β值或 b)。
logistic回归算法的系数必须从训练集中估计。
随机梯度下降
梯度下降是通过顺着成本函数(cost function)的梯度来最小化函数的过程。
这涉及到成本函数的形式及导数,使得从任意给定点能推算梯度并在该方向上移动,例如,沿坡向下(downhill)直到最小值。
在机器学习中,我们可以使用一种技术来评估和更新每次迭代后的系数,这种技术称为随机梯度下降,它可以使模型的训练误差(training error)最小化。
此优化算法每次将每个训练样本传入模型。模型对训练样本进行预测,计算误差并更新模型以便减少下一预测的误差。
该过程可以找到使训练误差最小的一组系数。每次迭代,机器学习中的系数(b)通过以下等式更新:
b = b + learning_rate * (y - yhat) * yhat * (1 - yhat) * x
其中 b 是被优化的系数或权重,learning_rate 是必须设置的学习速率(例如0.01),(y - y hat)是训练数据基于权重计算的模型预测误差,y hat 是通过系数计算的预测值,x是输入值。
Pima 印第安人糖尿病数据集
Pima Indians 数据集包含了根据基本医疗细节预测 Pima 印第安人5年内糖尿病的发病情况。
它是一个二元分类问题,其中预测是 0(无糖尿病)或 1(糖尿病)。
它包含 768 行和 9 列。 所有值都是数字型数值,含有浮点值(float)。下面的例子展示了数据前几行的结构。

通过预测多数类(零规则算法 Zero Rule Algorithm),这个问题的基线性能为 65.098%的分类准确率(accuracy)。你可以在 UCI 机器学习数据库中了解有关此数据集的更多信息: https://archive.ics.uci.edu/ml/datasets/Pima+Indians+Diabetes
下载数据集,并将其保存到你当前的工作目录,文件名为 pima-indians-diabetes.csv。
教程
本教程分为3部分。
1.进行预测
2.估计系数
3.糖尿病数据集预测
学完这三部分,你将具有应用 logistic 回归与随机梯度下降的基础,并可以开始处理你自己的预测建模问题。
1.进行预测
第一步是开发一个可以进行预测的函数。
在随机梯度下降中估计系数值以及模型最终确定后在测试集上进行预测都需要这个预测函数。
下面是一个名为 predict()的函数,给定一组系数,它预测每一行的输出值。
第一个系数始终为截距项(intercept),也称为偏差或 b0,因为它是独立的,不是输入值的系数。
# Make a prediction with coefficients
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row)-1):
yhat += coefficients[i + 1] * row[i]
return 1.0 / (1.0 + exp(-yhat))
我们可以设计一个小数据集来测试我们的 predict()函数。
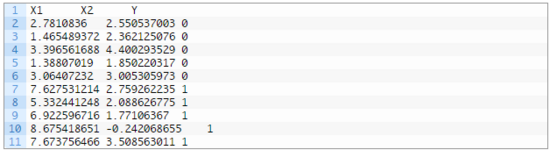
下面是数据集的散点图,不同颜色代表不同类别。
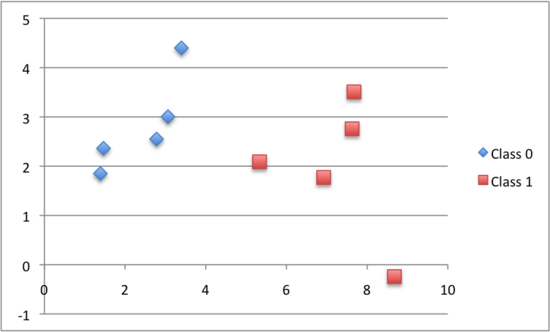
我们还可以使用先前准备的系数对该数据集进行预测。
把这些放在一起,我们可以测试下面的 predict()函数。
# Make a prediction
from math import exp
# Make a prediction with coefficients
def predict ( row , coefficients ) :
yhat = coefficients [ 0 ]
for i in range ( len ( row ) - 1 ) :
yhat += coefficients [ i + 1 ] * row [ i ]
return 1.0 / ( 1.0 + exp ( - yhat ) )
# test predictions
dataset = [ [ 2.7810836 , 2.550537003 , 0 ] ,
[ 1.465489372 , 2.362125076 , 0 ] ,
[ 3.396561688 , 4.400293529 , 0 ] ,
[ 1.38807019 , 1.850220317 , 0 ] ,
[ 3.06407232 , 3.005305973 , 0 ] ,
[ 7.627531214 , 2.759262235 , 1 ] ,
[ 5.332441248 , 2.088626775 , 1 ] ,
[ 6.922596716 , 1.77106367 , 1 ] ,
[ 8.675418651 , - 0.242068655 , 1 ] ,
[ 7.673756466 , 3.508563011 , 1 ] ]
coef = [ - 0.406605464 , 0.852573316 , - 1.104746259 ]
for row in dataset :
yhat = predict ( row , coef )
print ( "Expected=%.3f, Predicted=%.3f [%d]" % ( row [ - 1 ] , yhat ,round ( yhat ) ) )
有两个输入值(X1 和 X2)和三个系数(b0,b1 和 b2)。该模型的预测方程是:
y = 1.0 / (1.0 + e^(-(b0 + b1 * X1 + b2 * X2)))
或者,代入我们主观选择的具体系数值,方程为:
y = 1.0 / (1.0 + e^(-(-0.406605464 + 0.852573316 * X1 + -1.104746259 * X2)))
运行此函数,我们得到的预测值相当接近预期的输出值(y),并且四舍五入时能预测出正确的类别。
现在我们已经准备好实现随机梯度下降算法来优化系数值了。
2.估计系数
我们可以使用随机梯度下降来估计训练集的系数值。
随机梯度下降需要两个参数:
学习速率(Learning Rate):用于限制每次迭代时每个系数的校正量。
迭代次数(Epochs):更新系数前遍历训练集数据的次数。
函数中有 3 层循环:
1.每次迭代(epoch)的循环。
2.每次迭代的训练集数据的每一行的循环。
3.每次迭代的每一行数据的每个系数的每次更新的循环。
就这样,在每一次迭代中,我们更新训练集中每一行数据的每个系数。系数的更新基于模型的训练误差值。这个误差通过期望输出值(真实的因变量)与估计系数确定的预测值之间的差来计算。
每一个输入属性(自变量)对应一个系数,这些系数在迭代中不断更新,例如:
b1(t+1) = b1(t) + learning_rate * (y(t) - yhat(t)) * yhat(t) * (1 - yhat(t)) * x1(t)
列表开头的特殊系数(也称为截距)以类似方式更新,除了与输入值无关:
b0(t+1) = b0(t) + learning_rate * (y(t) - yhat(t)) * yhat(t) * (1 - yhat(t))
现在我们可以把这所有一切放在一起。下面是一个名为 coefficients_sgd()的函数,它使用随机梯度下降计算训练集的系数值。
# Estimate logistic regression coefficients using stochastic gradient descent
def coefficients_sgd(train, l_rate, n_epoch):
coef = [0.0 for i in range(len(train[0]))]
for epoch in range(n_epoch):
sum_error = 0
for row in train:
yhat = predict(row, coef)
error = row[-1] - yhat
sum_error += error**2
coef[0] = coef[0] + l_rate * error * yhat * (1.0 - yhat)
for i in range(len(row)-1):
coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 - yhat) * row[i]
print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error))
return coef
此外,每次迭代我们记录误差平方和 SSE(一个正值),以便我们在每个外循环开始时可以print出结果。
我们可以用上面的小数据集测试这个函数。
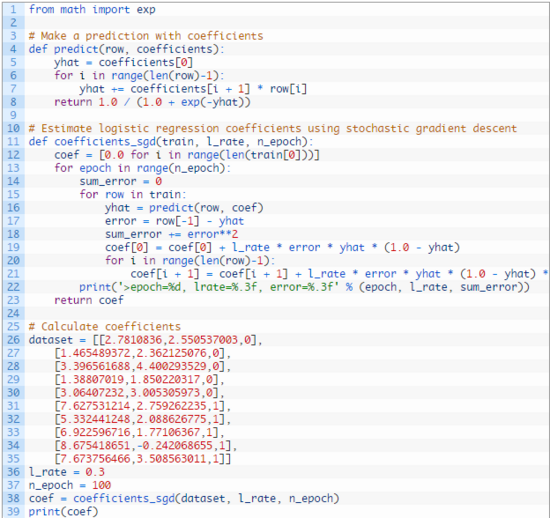
我们使用更大的学习速率 0.3,并循环 100 次迭代来训练模型,或将系数更新 100 次。
运行该示例代码,每次迭代时会print出该次迭代的误差平方和以及该迭代确定的最优系数。

你可以看到误差持续下降,甚至在最后一次迭代。我们可以训练更长的时间(更多次迭代)或增加每次迭代更新系数的程度(更高的学习率)。
<span style="font-family: 微软雅黑, 'Microsoft YaHei'; font-size: 16px;">测试这些代码,看看你有什么新想法。<br />现在,让我们将此算法应用于实际数据集。<br /></span>
<span style="font-family: 微软雅黑, 'Microsoft YaHei'; font-size: 16px;"><br /></span>
3.糖尿病数据集预测
在本节中,我们将使用随机梯度下降算法对糖尿病数据集进行logistic回归模型训练。
该示例假定数据集的 CSV 副本位于当前工作目录中,文件名为 pima-indians-diabetes.csv。
首先加载数据集,将字符串值转换为数字,并将每个列标准化为 0到1 范围内的值。这是通过辅助函数 load_csv()和 str_column_to_float()来加载和准备数据集以及 dataset_minmax()和 normalize_dataset()来标准化的。
我们将使用k折交叉验证(k-fold cross validation)来估计学习到的模型在未知数据上的预测效果。这意味着我们将构建和评估 k 个模型,并将预测效果的平均值作为模型的评价标准。分类准确率将用于评估每个模型。这些过程由辅助函数 cross_validation_split(),accuracy_metric() 和 evaluate_algorithm()提供。
我们将使用上面创建的 predict()、coefficients_sgd()函数和一个新的 logistic_regression()函数来训练模型。
下面是完整示例:
# Logistic Regression on Diabetes Dataset
from random import seed
from random import randrange
from csv import reader
from math import exp
# Load a CSV file
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# Convert string column to float
def str_column_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# Find the min and max values for each column
def dataset_minmax(dataset):
minmax = list()
for i in range(len(dataset[0])):
col_values = [row[i] for row in dataset]
value_min = min(col_values)
value_max = max(col_values)
minmax.append([value_min, value_max])
return minmax
# Rescale dataset columns to the range 0-1
def normalize_dataset(dataset, minmax):
for row in dataset:
for i in range(len(row)):
row[i] = (row[i] - minmax[i][0]) / (minmax[i][1] - minmax[i][0])
# Split a dataset into k folds
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = len(dataset) / n_folds
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# Calculate accuracy percentage
def accuracy_metric(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# Evaluate an algorithm using a cross validation split
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algorithm(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
return scores
# Make a prediction with coefficients
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row)-1):
yhat += coefficients[i + 1] * row[i]
return 1.0 / (1.0 + exp(-yhat))
# Estimate logistic regression coefficients using stochastic gradient descent
def coefficients_sgd(train, l_rate, n_epoch):
coef = [0.0 for i in range(len(train[0]))]
for epoch in range(n_epoch):
for row in train:
yhat = predict(row, coef)
error = row[-1] - yhat
coef[0] = coef[0] + l_rate * error * yhat * (1.0 - yhat)
for i in range(len(row)-1):
coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 - yhat) * row[i]
return coef
# Linear Regression Algorithm With Stochastic Gradient Descent
def logistic_regression(train, test, l_rate, n_epoch):
predictions = list()
coef = coefficients_sgd(train, l_rate, n_epoch)
for row in test:
yhat = predict(row, coef)
yhat = round(yhat)
predictions.append(yhat)
return(predictions)
# Test the logistic regression algorithm on the diabetes dataset
seed(1)
# load and prepare data
filename = 'pima-indians-diabetes.csv'
dataset = load_csv(filename)
for i in range(len(dataset[0])):
str_column_to_float(dataset, i)
# normalize
minmax = dataset_minmax(dataset)
normalize_dataset(dataset, minmax)
# evaluate algorithm
n_folds = 5
l_rate = 0.1
n_epoch = 100
scores = evaluate_algorithm(dataset, logistic_regression, n_folds, l_rate, n_epoch)
print('Scores: %s' % scores)
print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores))))
令 k 折交叉验证的k值为5,每次迭代时用于评估的数量为 768/5 = 153.6 或刚好超过150个记录。通过实验选择学习速率 0.1 和训练迭代次数 100。
你可以尝试其它的设置,看看模型的评估分数是否比我的更好。
运行此示例代码,print 5折交叉验证的每一次的分数,最后print分类准确率的平均值。
可以看到,此算法的准确率大约为 77%,而如果我们使用零规则算法预测多数类,基线值为 65%,本算法的准确率高于基线值。
