阿布云
你所需要的,不仅仅是一个好用的代理。
Python中自然语言的处理

在本文教会你使用pandas和python的自然语言工具包分析你Gmail邮箱中的内容.
NLP-风格的项目充满无限可能:
- 情感分析是对诸如在线评论、社交媒体等情感内容的测度.举例来说,关于某个话题的tweets趋向于正面还是负面的意见?一个新闻网站涵盖的主题,是使用了更正面/负面的词语,还是经常与某些情绪相关的词语?这个“正面”的Yelp点评不是很讽刺么?
- 分析语言在文学中的使用,进而衡量词汇或者写作风格随时间/地区/作者的变化趋势.
- 通过识别所使用的语言的关键特征,标记是否为垃圾内容.
- 基于评论所覆盖的主题,使用主题抽取进行相似类别的划分.
- 通过NLTK’s的语料库,应用Elastisearch和WordNet的组合来衡量Twitter流API上的词语相似度,进而创建一个更好的实时Twitter搜索.
- 加入NaNoGenMo项目,用代码生成自己的小说,你可以从这里大量的创意和资源入手.
将Gmail收件箱加载到pandas
让我们从项目实例开始!首先我们需要一些数据.准备你的Gmail的数据存档(包括你最近的垃圾邮件和垃圾文件夹).
https://www.google.com/settings/takeout
现在去散步吧,对于5.1G大小的信箱,我2.8G的存档需要发送一个多小时.
当你得到数据并为工程配置好本地环境之后好,使用下面的脚本将数据读入到pandas(强烈建议使用IPython进行数据分析)
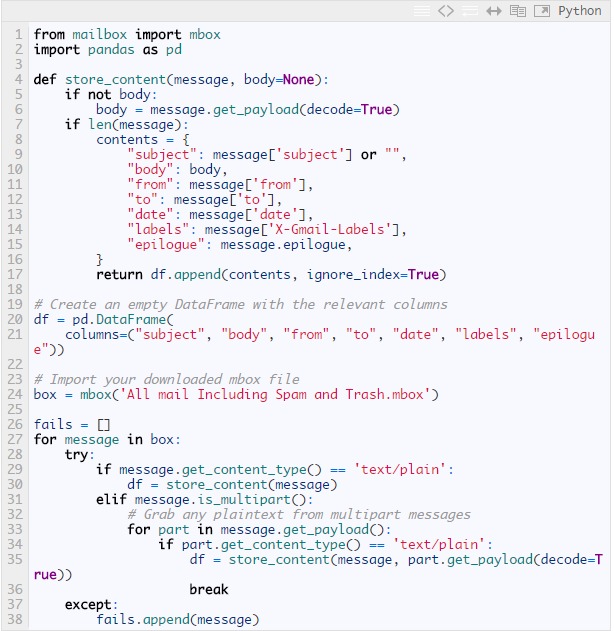
上面使用Python的mailbox模块读取并解析mbox格式的邮件,当然还可以使用更加优雅的方法来完成(比如,邮件中包含大量冗余、重复的数据,像回复中嵌入的“>>>”符号).另外一个问题是无法处理一些特殊的字符,简单起见,我们进行丢弃处理;确认你在这一步没有忽略信箱中重要的部分.
需要注意的是,除了主题行,我们实际上并不打算利用其它内容.但是你可以对时间戳、邮件正文进行各种各样有趣的分析,通过标签进行分类等等。鉴于这只是帮助你入门的文章(碰巧会显示来自我自己信箱中的结果),我不想去考虑太多细节.
查找常用词语
现在我们已经得到了一些数据,那么来找出所有标题行中最常用的10个词语:
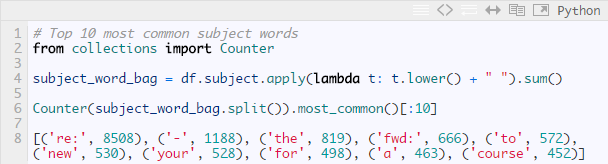
嗯,那些太常见了,下面尝试对常用词语做些限制:
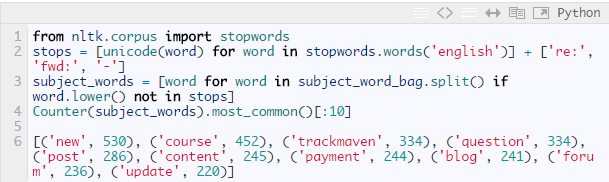
除了人工移除几个最没价值的词语,我们也使用了NLTK的停用词语料库,使用前需要进行傻瓜式安装.
二元词组和搭配词
NLTK可以进行另外一个有趣的测量是搭配原则.首先,我们来看下常用的“二元词组”,即经常一起成对出现的两个单词的集合:
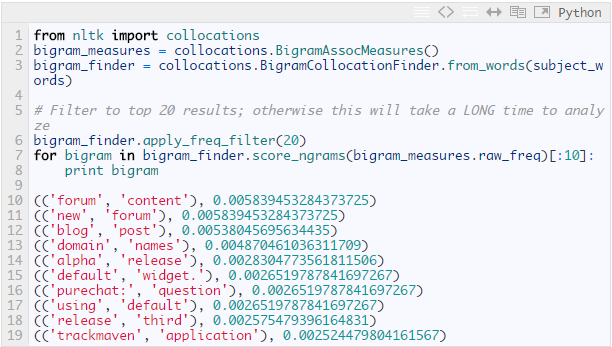
我们可以对三元词组(或n元词组)重复相同的步骤来查找更长的短语.这个例子中,“new forum content”是出现次数最多的三元词组,但是在上面例子的列表中,它却被分割成两部分并位居二元词组列表的前列.
另外一个稍微不同类型的搭配词的度量是基于点间互信息(pointwise mutual information)的.本质上,它所度量的是给定一个我们在指定文本中看到的单词,相对于他们通常在全部文档中单独出现的频率,另外一个单词出现的可能性.举例来说,通常,如果我的邮件主题使用单词“blog”与/或“post”很多,那么二元组“blog post”并不是一个有趣的信号,因为一个单词仍然可能不和另一个单词同时出现.根据这条准则,我们得到一个不同的二元组的集合.
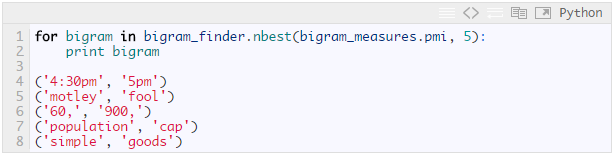
因此,我没有收到很多提到单词“motley”或者“fool”的邮件主题,但是当我看到其中任意一个,那么“Motley Fool”可能是相关联的.
情感分析
最后,让我们尝试一些情感分析.为了快速入门,我们可以使用以NLTK为基础的TextBlob库,它提供了对于大量的常用NLP任务的简单访问.我们可以使用它内建的情感分析(基于模式)来计算主题的“极性(polarity)”.从,表示高度负面情绪的-1到表示正面情绪的1,其中0为中性(缺乏一个明确的信号)
接下来:分析一段时间内的你的收件箱;看看是否能够通过邮件分类,确定正文的发送者/标签/垃圾这些基本属性.使用潜在语义索引去揭示所涵盖的最常用的常规主题.将你的发件文件夹输入到马尔科夫模型(Markov model)中,结合词性标注生成看起来连贯的自动回复