阿布云
你所需要的,不仅仅是一个好用的代理。
Python框架scikit
Python数据挖掘框架scikit数据集之iris
by briefcopy · Published 2016年6月3日 · Updated 2016年12月11日
一.iris数据集简介
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表。
通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。
iris的每个样本都包含了品种信息,即目标属性(第5列,也叫target或label)。
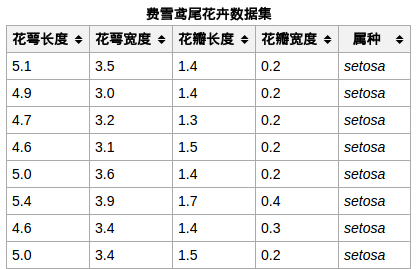
样本局部截图:
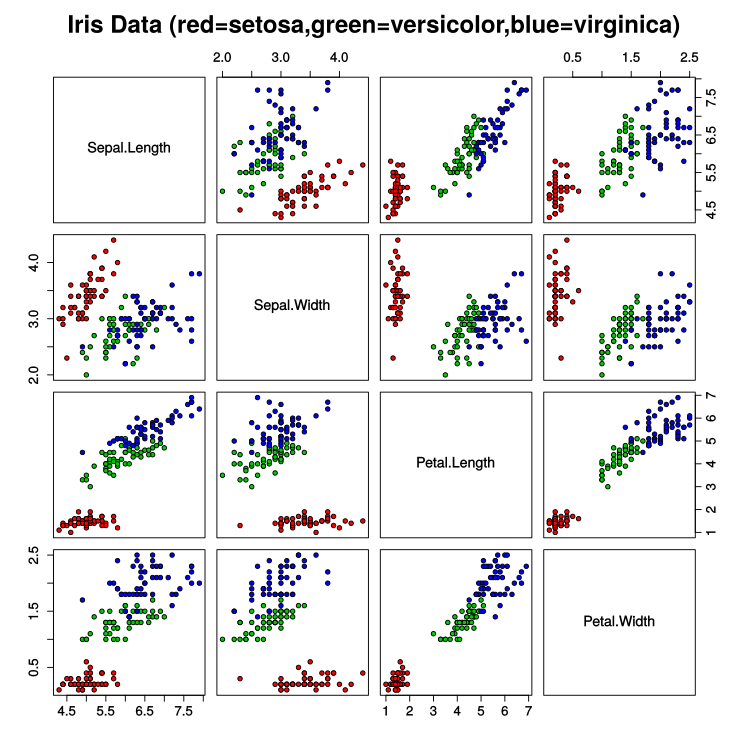
将样本中的4个特征两两组合(任选2个特征分别作为横轴和纵轴,用不同的颜色标记不同品种的花),可以构建12种组合(其实只有6种,另外6种与之对称),如图所示:
python的数据挖掘/机器学习库scikit已经内置了iris数据集,如果还没有安装scikit,可以参考scikit安装教程。
二.scikit中iris数据集简介
在linux中打开终端(ubuntu默认快捷键是ctrl+alt+T),输入python进入python shell,输入代码:
from sklearn import datasets iris=datasets.load_iris() #data对应了样本的4个特征,150行4列 print iris.data.shape #显示样本特征的前5行 print iris.data[:5] #target对应了样本的类别(目标属性),150行1列 print iris.target.shape #显示所有样本的目标属性 print iris.target
运行结果如下:
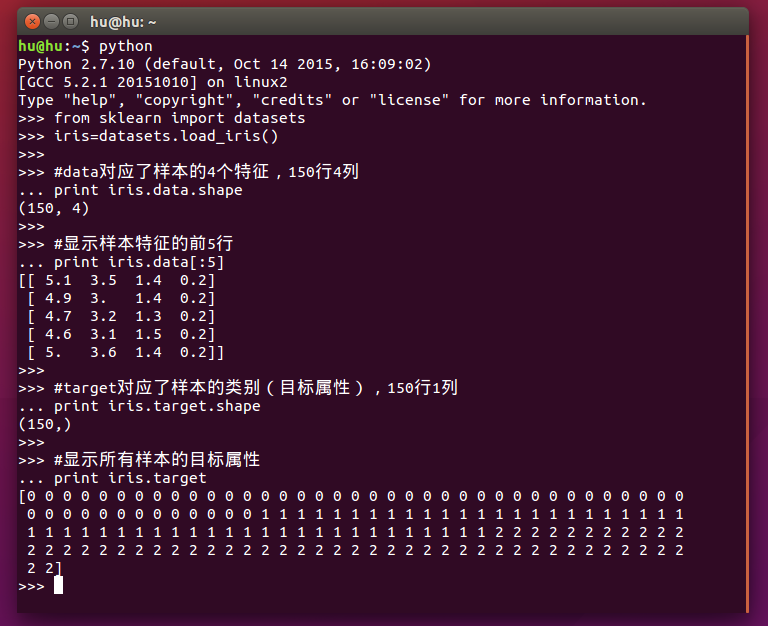
其中,iris.target用0、1和2三个整数分别代表了花的三个品种
阿布云高速代理IP,分布式动态代理IP,高质量IP代理,全国高匿代理ip,爬虫代理,私密代理IP,国内极速代理IP,优质代理IP
阿布云代理:https://www.abuyun.com