阿布云
你所需要的,不仅仅是一个好用的代理。
Python框架scikit教程
1.安装Ubuntu
不要在windows下折腾了,给自己找麻烦
2.安装依赖
依次输入命令:
sudo apt-get install build-essential python-dev python-setuptools \ python-numpy python-scipy \ libatlas-dev libatlas3gf-base
sudo update-alternatives --set libblas.so.3 \ /usr/lib/atlas-base/atlas/libblas.so.3 sudo update-alternatives --set liblapack.so.3 \ /usr/lib/atlas-base/atlas/liblapack.so.3
sudo apt-get install python-matplotlib
3.安装pip
下载get-pip.py
官方下载地址:https://bootstrap.pypa.io/get-pip.py
百度云下载地址:http://pan.baidu.com/s/1hsnV3wC
打开终端(Ubuntu快捷键是ctrl+alt+T),进入get-pip.py所在文件夹(如果用浏览器下载,一般在”/home/你的用户名/下载”这个目录),输入命令sudo python get-pip.py,回车执行
4.安装scikit-learn
执行命令:
sudo pip install scikit-learn
5.验证scikit安装是否成功
打开终端,输入python进入python shell
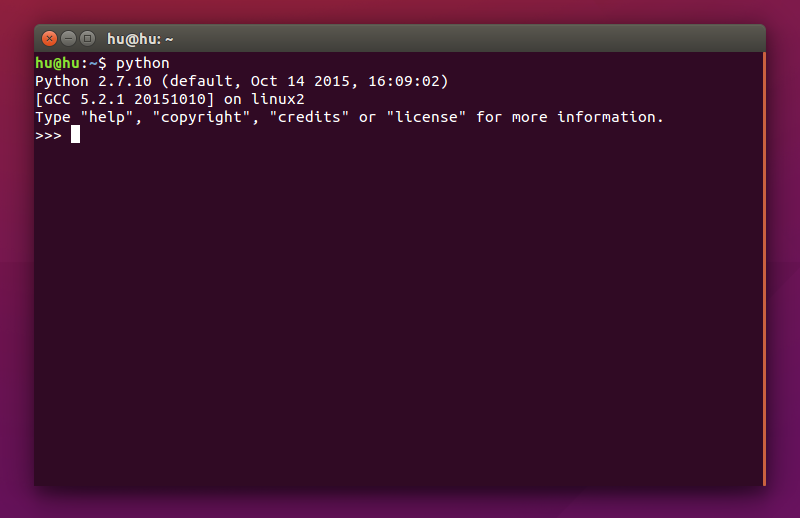
输入一段示例代码(对4个数据点执行k-means聚类):
from sklearn.cluster import KMeans data=[[0,0],[0,1],[30,31],[31,32]] kmeans=KMeans(n_clusters=2); kmeans.fit(data); print kmeans.labels_
可以复制上面代码,然后用快捷键ctrl+shift+v粘贴到终端,如果安装成功,回车后应该出现如下结果:
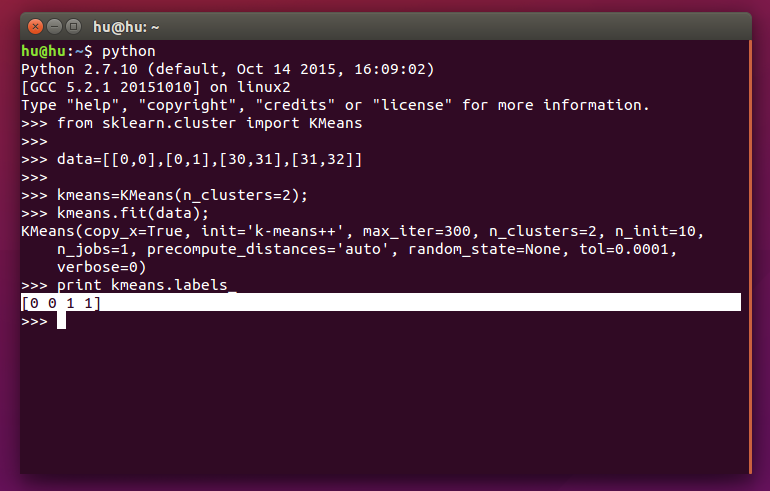
被标记为白色的一行是程序的运行结果,表示4个数据点分别所属的类别。
6.验证matplotlib是否安装成功
matplotlib是python数据可视化的一个库,scikit官方给的很多例子都使用matplotlib来展示数据挖掘的结果
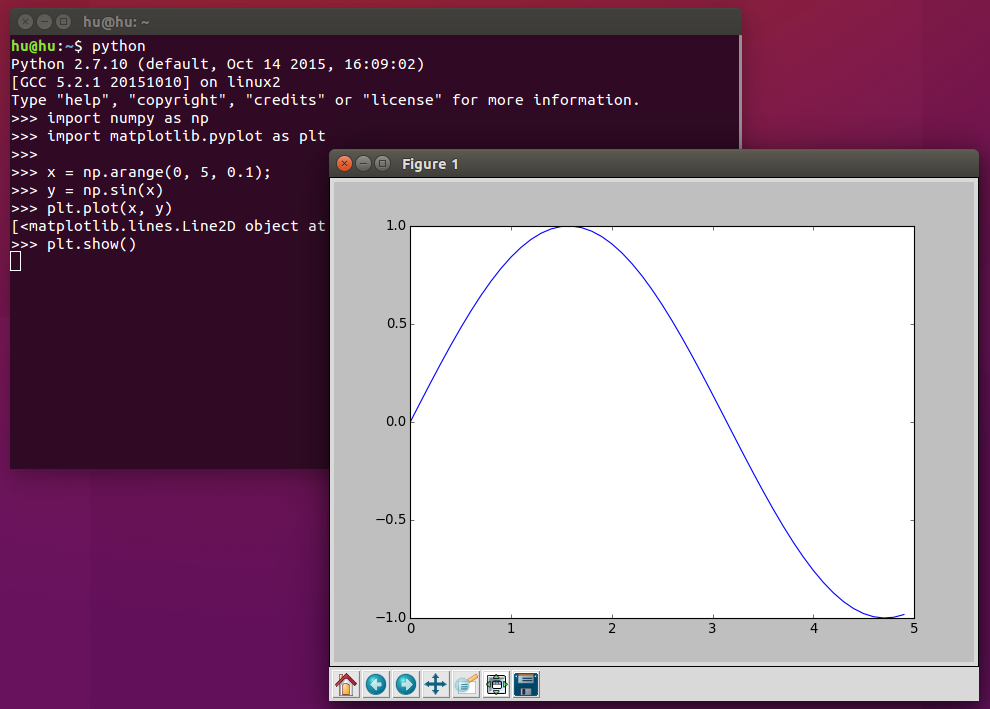
打开终端,输入python进入python shell,输入代码:
import numpy as np import matplotlib.pyplot as plt x = np.arange(0, 5, 0.1); y = np.sin(x) plt.plot(x, y) plt.show()
回车后如果出现绘制出如下统计图,说明matplotlib安装成功:
阿布云高速代理IP,分布式动态代理IP,高质量IP代理,全国高匿代理ip,爬虫代理,私密代理IP,国内极速代理IP,优质代理IP
阿布云代理IP:https://www.abuyun.com
http://datahref.com